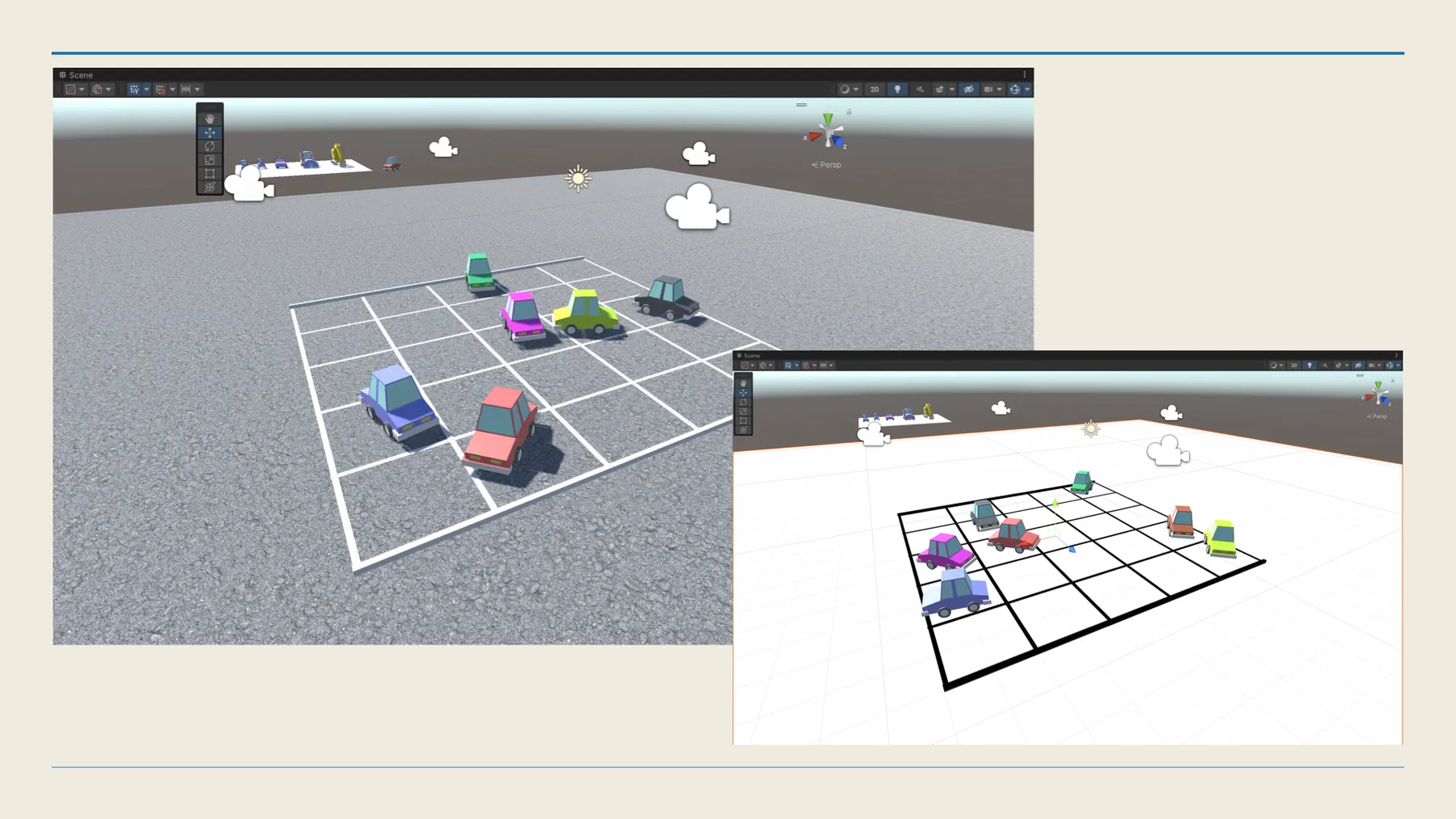
This project started as a research question: can a model generate a convincing new view of a three-dimensional scene from only a limited number of existing views? I approached it through conditional GANs and built a controlled Unity setup to generate the data I needed.
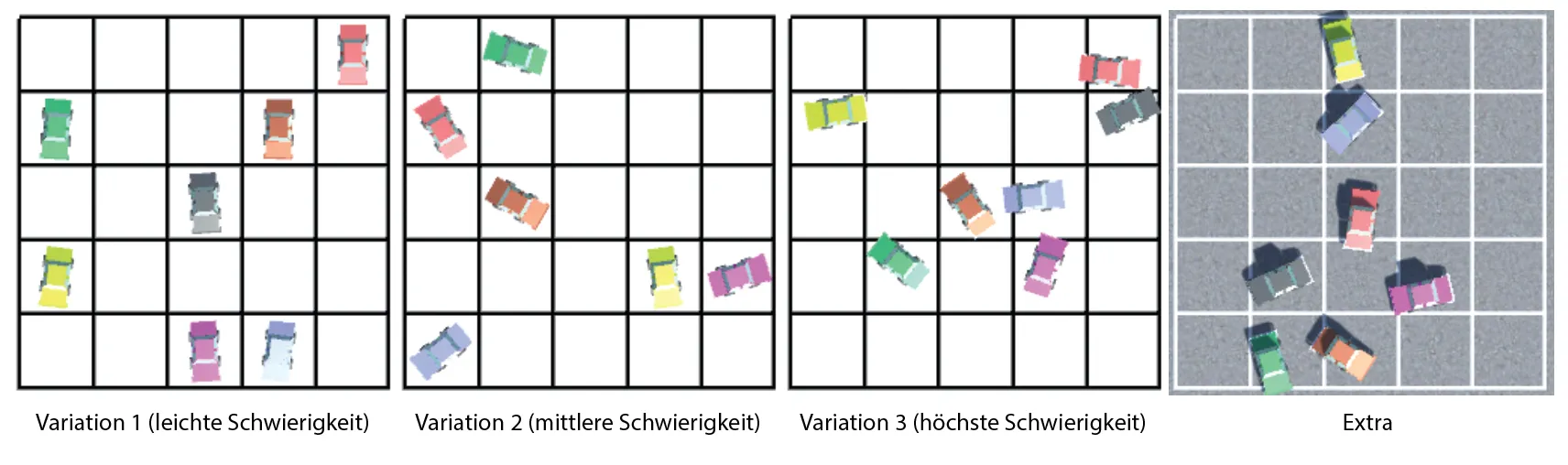
To make the experiments comparable, I created several difficulty levels. Simpler scenes worked better, while more complex ones exposed the limits of the models pretty quickly. That contrast was useful because it made the strengths and weaknesses of each approach much easier to see. One practical use case I had in mind was automotive systems, especially around parking and camera-assisted navigation.
What I liked most about the project was the mix of theory and implementation. It was not just about reading papers. I also had to generate data, run experiments, compare outputs, and turn the whole process into a written result that was clear enough to explain to other people. The final paper was later published on figshare.